How many parts is something I can’t yet answer. As many as it takes.
The SDE is a Static Data Extract from Eve Online. It contains information like where stars and planets are, how much Tritanium goes into a Typhoon, what skills are needed for which modules and so on. It’s a useful bag of information if you’re going to be doing any development of third party tools for the game. Much (but not all) of the information is also available directly from ESI, where it’s potentially more up to data. However, it can be a lot more time consuming to process there, and some is just not available. Like what blueprints need.
The official SDE direct from CCP
I’m not going to go into a great deal of depth on this. It’s not what most people use.
From https://developers.eveonline.com/resource/resources you can download the file sde-TRANQUILITY.zip
This is the main source for the SDE, and what I use to create my own versions. The main reason most people don’t use is, is that it’s a fuckton (metric, not imperial) of yaml files. Great for passing data around, not so good for looking up something.
CCP tend to update this a wee while after a release happens. Sometimes they need poked to do it. If you’re going to work directly from it, be aware that not all yaml parsers are created equal and can handle the spec a little differently. pyYAML is probably the one to use if you can, with libyaml to stop it taking forever.
The SDE release from yours truly
For a little history, CCP used to release the SDE as a MS SQL server dump. When I got started, someone else did the conversions to mysql which I used. Then they got slower and slower, and I got impatient, finally working out how to do it myself. A few years later, CCP started converting how they did their data versioning internally, moving from what they called BSD to FSD. Which meant they moved to yaml files for much of it. At this point, I totally rewrote the converter process I was using. And because I could, I set it to target a number of different database. If I get hit by a bus, you can find it at https://github.com/fuzzysteve/yamlloader It’s python 2.7, but should be simple enough to convert to 3 if you want to.
https://www.fuzzwork.co.uk/dump/ is where I keep the conversions. I don’t promise to keep them for all time, but older versions are available if you want them. the latest version is always in the latest folder or linked to with the latest links in the root.
If you’re wondering about the structure and names, most of that is a hold over from the original SDE, so that applications needed minimal changes.
Available are:
- MySQL, both a complete dump, and individual tables
- SQLite, a complete database file.
- Postgresql, pg_dump file for use with pg_restore
- the normal one, which puts all the tables into the public schema
- the ‘schema’ one, which puts all the tables into the evesde schema. I recommend this one for people starting out with postgres. Easier to update.
- MS SQL server, a Data Tier Application export.
- CSV files, now in gzip, bzip2, and plain format.
The Tables (In my conversion)
There are many tables (or CSV files) in the Eve SDE. However, these tend to fall into a small number of groups only a few of which are wanted.
The ‘Stuff’ tables
invTypes
This is the core table for many applications. If you have something which isn’t a unique item, then this is probably where you’ll want to look it up. Have a typeID from ESI which you want to look up? This is that table. Skills, ships, trade goods, generic planet types, all that good stuff. There’s a published column here which basically says whether it’s actively in the game or not.
invGroups and invCategories
invTypes has a groupID column. That links to invGroups, which has a categoryID which links to invCategories. invCategories contains a list of the types of stuff which exist. Like Ships, Skills, Planets, Modules, and so on. invGroups breaks that down further to things like Assault Frigates, Battleships, Science Skills, Asteroids and so on.
Example: you want all the ships in the game. you look up invCategories and find that ships are categoryID 6 (rather than always joining in the invCategories table.)
select typeName from invTypes join invGroups on invTypes.groupID=invGroups.groupID and invGroups.categoryID=6;
invMarketGroups
Much like invGroups, invMarketGroups is referred to by marketGroupID in invTypes. a little complexity is added, because each market group can have a parentMarketGroupID. This is so you can have each assault frigate in a market group for their race, that market group in the assault frigates group, that market group in advanced frigates, that in Frigates, and that in Ships. (ships doesn’t have a parent). Getting the full tree in pure SQL is a complete pain in the ass.
invMetaGroups and invMetaTypes
invMetaGroups defines the various meta level groups. Like tech 1, tech 2, faction and so on. invMetaTypes links that back to invTypes so you can list all the T2 ships by joining it in. It also has the parentTypeID in case you want to see what the T1 version is.
select typeName from invTypes join invGroups on invTypes.groupID=invGroups.groupID and invGroups.categoryID=6 join invMetaTypes on invTypes.typeID=invMetaTypes.typeID and invMetaTypes.metaGroupID=2
invTraits
All those handy ship bonuses have to live somewhere. Links to invTypes for the ship type (typeID) and to invTypes for the skill (skillID). -1 is a bonus which isn’t related to a skill. unitID links to eveUnits so you know if it’s a percentage or what.
invFlags
This is related to the asset table in Eve. If you get back a list of your assets, they’ll have flags on them. You won’t see hangars and so on. The Flags determine where they are. Something with flag 11 is in the first lowslot on a ship, for example. This is why shared hangars are painful to implement.
invTypeMaterials
This _used_ to be used for making things. It’s not any more. it’s just what you get out of something when you recycle it. typeID links to invTypes for what you’re recycling, materialTypeID links to invTypes and is what you get out. quantity is what you’d get on a perfect (100%) refine.
invVolumes
When things change size as they’re packaged, the volume in invTypes becomes less useful. This is the volume of things which are packaged (when it’s different)
invItems
A table of unique items, where they are, who owns them and what they are. I don’t think I’ve ever seen anyone but CCP use this.
invNames and invUniqueNames
the names for the things in invItems. Don’t know what kind of something a thing is, but have an itemID? It might be in there. There’s almost always a better table to look at to get this information, because you normally know.
invPositions
Where the things in invItems are in space. like with invNames, it’s unlikely you’ll want to use this.
Industry Tables
When Crius came out, CCP changed up everything. And had a new yaml data file just for making shit. So I created a number of totally new tables from it. If you don’t like the format, it’s all my fault. Try and do better. I dare you.
A common column in these tables is the activityID column. This is to split them up into the various things you can do with a blueprint. Like manufacturing, researching TE, copying, reacting, inventing and so on. Yes, reactions are just blueprints like anything else now.
| 1 | Manufacturing |
| 3 | Researching Time Efficiency |
| 4 | Researching Material Efficiency |
| 5 | Copying |
| 8 | Invention |
| 11 | Reactions |
industryActivity
typeID is the blueprint typeid in invTypes. time is how long it takes to do that activity before modifiers.
industryActivityMaterials
Which materialTypeIDs from invTypes are used for an activityID when using a typeID (blueprint) from invTypes and the quantity before modifiers
industryActivityProducts
What quantity of productTypeIDs from invTypes are produced per run of a typeID (blueprint) from invTypes for a specific activityID
industryActivitySkills
What skillID from invTypes is required to do activityID on a typeID (blueprint) from invTypes and what level it needs to be.
industryActivityProbabilities
Invention has different probability depending on the typeID of the blueprint (invTypes) with a handy productTypeID to work out what it makes.
industryBlueprints
maxProductionLimit is how many blueprint copies can be on a BPC.
Planetary Interaction.
planetSchematics
The various things you can make on a planet and how long they take.
planetSchematicsPinMap
Just links the schematics to the kind of structure on planet which makes them. Like basic industry. though it is by planet type as well.
planetSchematicsTypeMap
Takes the schematicID from planetSchematics, and tells you the quantity of what typeIDs you need to put in (isInput=1) to get typeID out (isInput=0)
The Dogma Tables
Dogma is Eve’s engine for knowing stuff about things. What slot does a module go into? Dogma. What skills are required for something? Dogma. How much damage does a gun do? Dogma (though it’s hard to work out. yay)
dgmAttributeTypes
The table with the description of the various dogma Attributes. by attributeID
dgmTypeAttributes
The table which links dogma attributes attributeID to item types invTypes typeid. These days, just use valueFloat for the value. everything is condensed into that now. Handy for things like how many low slots something has. Or which skills are required. (with a separate attribute for which level it’s needed at. yay)
To see all the attributes and what they do, for a Rifter (typeid 587) try:
select * from dgmTypeAttributes join dgmAttributeTypes on dgmTypeAttributes.attributeID=dgmAttributeTypes.attributeID where typeID=587;dgmEffects
The various bits of dogma which are just flags on items, rather than things with values. like if it’s a low slot module or not. This describes those flags.
dgmTypeEffects
Linking typeID from invTypes to effectID in dgmEffects
dgmAttributeCategories
Just splits the various attributes up into categories. Like if it’s a fitting attribute, shield, or so on. categoryID in dgmAttributeTypes
dgmExpressions
This is stuff which relates to how things actually work in eve. the code behind it. I don’t understand it well enough to explain it.
Map Tables
mapDenormalize
This has pretty much every celestial in it, and where it is, in meters, in its star system, with the star at 0,0,0
Links to invTypes so you know what some is (planet etc) by typeID and invGroups by groupID. links to mapSolarSystems with solarSystemID, mapConstellations with constellationID mapRegions with regionID.
What might not be obvious is wormhole effects are here, with a groupid of secondary sun.
mapJumps
Less useful than it might sound, it tells you which pairs of stargates link up. You probably want mapSolarSystemJumps
mapSolarSystemJumps
what solarSystemIDs have stargates to what other solarSystemIDs. also has regions and constellations
mapSolarSystems
So you can find out information about solarsystems by solarSystemID. Names, regionIDs, ConstellationIDs, where they are in the universe in meters. (yes, light year ranges stored in meters) and their security rating.
mapRegions
Simiar information, but for Regions.
mapConstellations
Take a wild guess 😉
The end, for now
There are still a bunch of tables which I’ve not talked about yet. Most are pretty self explanatory, but I’ll get to them another time. This should be enough to get you going.
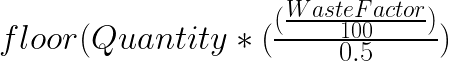

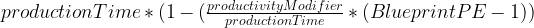
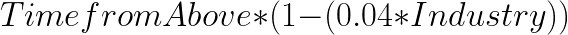
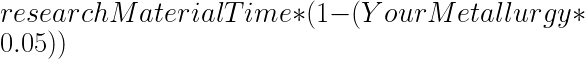


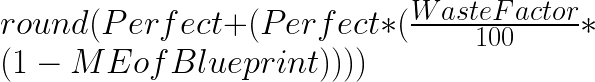
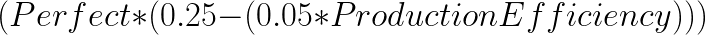 to your materials. You only do this for:
to your materials. You only do this for: